|
雷锋网按:本文为雷锋字幕组编译的技术博客,原标题 Regularization of Linear Models with SKLearn ,作者为 Robert John 。 翻译 | 姚秀清 整理 | MY
过拟合模型 线性模型通常是训练模型的一个比较好的起点。但是由于许多数据集的自变量和因变量之间并不是线性关系,所以经常需要创建多项式模型,导致这些模型很容易过拟合。正则化则是减少多项式模型过拟合的一种方法。 我们从构建基线模型开始来确定所需的改进。本文中我们将使用 Kaggle 中流行的 Boston Housing 数据集。 让我们导入所依赖的库并加载训练数据集。
将数据分成训练集和验证集,其中30%的数据用于验证。我们将使用随机状态使我们的实验可复制。
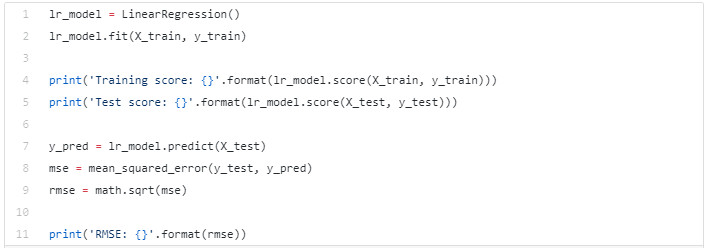
让我们通过训练线性回归模型建立基线。
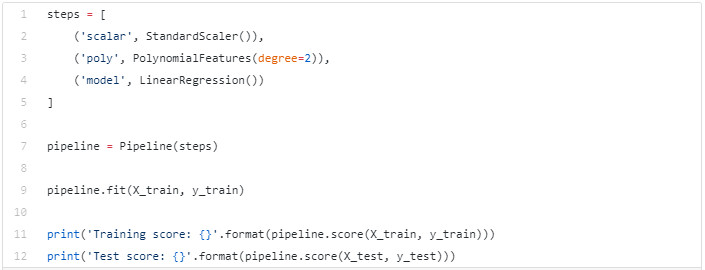
上述模型应得出约 72% 的训练精度和测试精度,以及 4.587 的 RMSE 。 训练的下一个模型应具有更高的准确度和更低的 RMSE ,其结果要优于该模型。 我们需要构造一些新的特征。 具体来说就是通过现有的一些特征来构造多项式特征,并通过提升特征到指定的幂来实现。幸运的是,scikit-learn 已经实现了该功能,我们不需要自己实现。 然后我们可以标准化数据。 这一步将使我们的数据缩小至 0 到 1 之间。这使得我们在提升功率时可以使用合理的数字。 最后,由于需要在训练集、验证集和测试集上执行相同的操作,我们引入了管道。 管道可以管理我们的流程,以便重复执行相同的步骤。 总结一下,我们一开始缩放数据,然后构造多项式特征,最后训练线性回归模型。
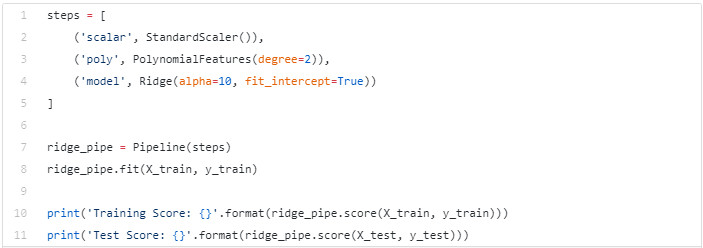
运行代码后,我们将获得约 94.75% 的训练精度,46.76% 的测试精度。 这样的结果通常是过拟合的, 所以新创建的特征不一定是理想的特征。 现在我们将在新的数据上使用正则化。 L2 正则化或岭回归 为了理解岭回归,我们需要注意在模型系数被训练时以及梯度下降期间发生了什么。 在训练时,我们使用了学习率和梯度及梯度更新规则来更新我们的初始权重。 岭回归为更新增加了一个惩罚项,因此缩小了权重的大小。 scikit-learn 的 Ridge 类就实现了该功能。 这次我们使用 Ridge 来创建一个新的管道,通过传入一个参数 alpha 来指定我们的正则化强度。 这个值可能非常小,比如 0.1,也有可能很大。 alpha 值越大,模型的变化越小。
通过运行代码,我们应该具有约 91.8% 的训练精度和 82.87% 测试精度。 这是我们改进后的基线线性回归模型。 让我们尝试一些别的方法。 L1 正则化或 Lasso 回归 通过创建多项式模型,我们构造了新的特征。但是需要确认哪些特征与我们的模型有关,哪些无关。 L1 正则化试图通过将某些系数的值降低到 0 来回答这个问题,这消除了我们模型中最不重要的特征。 我们将使用 Lasso 创建一个类似于上面的管道, 你可以使用范围是 0.1 到 1 的 alpha 值。
上述代码使我们的训练精度达到 84.8%,测试精度达到 83%。 这比我们之前训练的模型要好一些。 此时,您可以通过 RMSE 来评估模型。 不要忘记阅读我们引用的文档。 我希望这个教程对你很有帮助。 原文链接:https://medium.com/coinmonks/regularization-of-linear-models-with-sklearn-f88633a93a2 诞生啦! |

- 关注天气: